
こんにちは!株式会社雲海設計の技術部です。
「Claude Codeでエージェントを組んだら最初の数週間は調子が良かったのに、3ヶ月後に品質が崩れた」「PRごとに評価を回したいがCIが30分超えて止まった」「本番のClaude Codeセッションが何を壊しているのか追えない」——2025年後半からClaude Codeの本格導入が一気に進み、2026年に入ってからclaude code ハーネスエンジニアリングの相談が、技術部に毎週のように届いています。本記事では、claude code ハーネスエンジニアリングの実装パターンを、CIループ・回帰評価・本番監視という3層の業務適用視点で体系化し、コード例と運用フレーム付きで整理します。
TL;DR
Claude Codeのハーネスは「CIループ(PR単位)」「回帰評価(リリース単位)」「本番監視(運用単位)」の3層分離が2026年の標準形
CIループは3〜5分以内・10〜30ケースに絞り、PR ごとに必ず走らせる。これ以上重いと開発者が無視する
回帰評価は100〜500ケースのゴールドセットを週次/リリース前に回し、スコア低下を Slack 通知する
本番監視はサンプリング評価(1〜5%)+ ガードレール + コスト計測の3点セットで、劣化を早期検出する
評価モデルはSonnet 4.5を主軸、難所だけOpus 4.5に切り替える二階建てが、コストと精度のバランスで現実解
なぜ Claude Code にハーネスエンジニアリングが必須なのか?
結論から言うと、Claude Codeは「自律的にコードを書き、ファイルを編集し、コマンドを実行する」エージェントであり、出力の正しさを人間が毎回確認できないからです。プロンプトエンジニアリングだけでは、3ヶ月後の品質劣化を検知できません。
Gartnerが2026年初頭に発表したAIエージェント運用調査では、本番投入したコーディングエージェントの71%が「6ヶ月以内に何らかの品質劣化を経験」しており、そのうち58%は「評価ハーネスがなかったため、ユーザー報告まで気づけなかった」と回答しています。
つまりハーネスは「あれば便利」ではなく、Claude Codeを業務適用するための前提インフラです。ハーネスの基本思想についてはハーネスエンジニアリングとは?LLM時代に必須の新常識を解説で整理しているので、概念から押さえたい方はそちらも併読してください。
従来のテストとの違いは?
単体テスト・E2Eテストとハーネスは目的が違います。ハーネスは「LLMの確率的な振る舞いを定量化する」ための継続評価装置であり、同じ入力でも出力が揺らぐ前提で設計します。
| 項目 | 従来テスト | ハーネス |
|---|---|---|
| 合否判定 | 決定論的(pass/fail) | 確率的(スコア分布) |
| 評価者 | アサーション | LLM-as-a-Judge + ルール |
| 頻度 | PR ごと | PR/週次/本番サンプリング |
| 失敗の意味 | バグ | 劣化 or 仕様変化のシグナル |
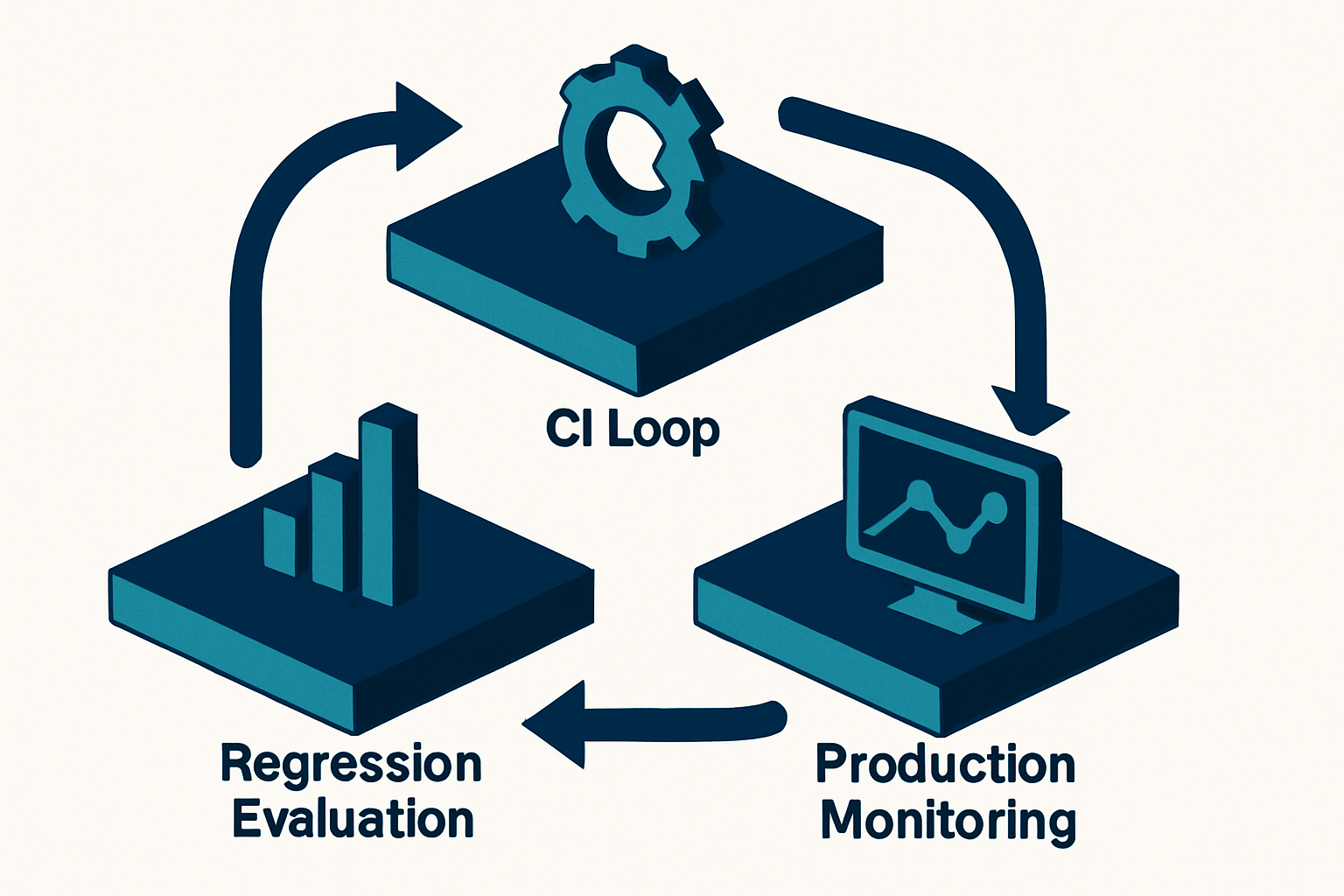
3層ハーネスの全体像はどうなる?
結論として、Claude Code のハーネスはCI・回帰・本番の3層で「速度」と「網羅性」のトレードオフを使い分けるのが業務適用の最適解です。
graph LR
A[開発者PR] --> B[CIループ
10-30ケース
3-5分]
B --> C[マージ]
C --> D[回帰評価
100-500ケース
週次/リリース前]
D --> E[本番デプロイ]
E --> F[本番監視
1-5%サンプリング
常時]
F -- 劣化検知 --> G[Slack通知]
G --> A各層の責務を明確に分ける
CIループ: 開発者の手を止めない速さで、最小限の品質ゲートを通す
回帰評価: 過去の成功ケースを壊していないかを網羅的に確認する
本番監視: 想定外の入力分布に対する劣化を検出する
3層を1つに統合しようとすると、「CIが重すぎて止まる」「回帰が浅すぎて取りこぼす」「本番監視がない」のどれかが必ず犠牲になります。分離が鉄則です。
CIループはどう実装する?
結論、3〜5分以内・10〜30ケース・スモークテスト的なゴールドセットで構成します。PRごとに走らせ、失敗したらマージブロックする運用です。
Claude Code SDK を使った最小実装例
import anthropic
import json
from pathlib import Path
client = anthropic.Anthropic()
def run_claude_code_task(task: dict) -> dict:
"""Claude Codeに1ケースを実行させる"""
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
system="You are a coding agent. Output a unified diff only.",
messages=[{"role": "user", "content": task["prompt"]}],
)
return {"diff": response.content[0].text, "usage": response.usage}
def judge(task: dict, output: dict) -> float:
"""LLM-as-a-Judge でスコアリング (0.0-1.0)"""
judge_prompt = f"""
タスク: {task['prompt']}
期待される変更: {task['expected']}
実際の出力: {output['diff']}
0.0-1.0でスコアし、JSON {{"score": float, "reason": str}} で返答。
"""
resp = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=512,
messages=[{"role": "user", "content": judge_prompt}],
)
return json.loads(resp.content[0].text)["score"]
def main():
cases = json.loads(Path("harness/ci_cases.json").read_text())
results = [judge(c, run_claude_code_task(c)) for c in cases]
avg = sum(results) / len(results)
print(f"avg_score={avg:.3f}")
exit(0 if avg >= 0.80 else 1)
if __name__ == "__main__":
main()GitHub Actions への組み込み
name: claude-code-harness
on: [pull_request]
jobs:
harness:
runs-on: ubuntu-latest
timeout-minutes: 8
steps:
- uses: actions/checkout@v4
- run: pip install anthropic
- run: python harness/ci_runner.py
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}合格閾値は0.80〜0.85から始め、運用しながら調整します。最初から0.95を目指すと、揺らぎで誤検知が頻発し開発者の信頼を失います。評価ループの設計詳細はClaude Codeで実装する評価ループ構築完全ガイドもあわせて参考にしてください。
回帰評価はどう設計する?
結論、過去に解決した課題・実際の本番ログから抽出した代表ケース・既知のエッジケースを100〜500件のゴールドセット化し、リリース前や週次で回します。
ゴールドセットの作り方
本番ログから代表ケースを抽出: タスク種別・難易度でクラスタリングし、各クラスタから5〜10件サンプリング
過去のインシデント由来ケースを必ず含める: 「二度と壊さない」ことを保証する
合成データで境界条件を補強: 巨大ファイル・空入力・多言語混在など
3ヶ月ごとに5〜10%を入れ替え: モデル側が過学習しないように
スコアの可視化と通知
回帰評価のスコアはカテゴリ別・難易度別に時系列で可視化します。全体平均だけ見ていると、「特定カテゴリだけ崩れている」のを見逃します。
| カテゴリ | 前回 | 今回 | 差分 | アクション |
|---|---|---|---|---|
| リファクタ | 0.89 | 0.87 | -0.02 | 許容範囲 |
| バグ修正 | 0.84 | 0.71 | -0.13 | 要調査 |
| 新機能追加 | 0.78 | 0.79 | +0.01 | OK |
| テスト生成 | 0.92 | 0.93 | +0.01 | OK |
差分が-0.05を超えたカテゴリは、Slack に自動通知してオーナーがアサインされる仕組みにします。「気づける構造」を先に作るのがハーネス運用の肝です。
本番監視はどう仕込む?
結論、サンプリング評価・ガードレール・コスト計測の3点セットで、24時間動き続ける劣化検知レイヤを作ります。
サンプリング評価の仕組み
全リクエストを評価するとコストが2倍になるので、1〜5%をランダムサンプリングし、非同期で LLM-as-a-Judge を回します。スコア分布が前週と比べて統計的に有意にずれた場合、アラートを発火させます。
import random
def should_evaluate(rate: float = 0.03) -> bool:
return random.random() < rate
async def handle_request(req):
result = await claude_code_run(req)
if should_evaluate():
await enqueue_judge_job(req, result) # 非同期キューへ
return resultガードレールとの組み合わせ
本番監視は「事後検知」なので、事前に止めるガードレールと組み合わせるのが鉄則です。危険なコマンド実行・機密情報の書き出し・想定外の外部API呼び出しなどは、ハーネスではなくガードレール側で止めます。具体的な設計パターンはハーネスエンジニアリング ガードレール設計で深掘りしています。
コスト計測も評価指標
「品質が同じでもコストが2倍」は劣化と同義です。タスク種別×モデル×平均トークンをダッシュボード化し、コスト/タスクのKPIを置きます。Claude Code を Bedrock 経由で運用する場合は、Claude Code × VSCode × Bedrock 実践構築ガイドで扱ったCost Allocation Tagと組み合わせると、人別・案件別の按分まで見えるようになります。
雲海設計の支援パターン
当社では2025年後半から、Claude Code をはじめとするコーディングエージェントの業務適用案件で、ハーネスをセットで導入する支援を行っています。実プロジェクトで見えた要点は次の3つです。
最初の2週間でCIループだけ立ち上げる: 完璧を狙わず、10ケース・3分のハーネスを先に動かす
1ヶ月目に回帰評価のゴールドセットを整備: 本番ログが溜まり始めるタイミングと合わせる
3ヶ月目から本番監視と原価管理を統合: コストKPIと品質KPIを同じダッシュボードに乗せる
ハーネスの実装単体ではなく、DXソリューションやITコンサルティングの文脈で、運用設計込みで伴走するのが当社の型です。
よくある質問
Q. ハーネスのゴールドセットは何件から始めればいい?
A. CIループは10〜30件、回帰評価は100件から始めるのが現実的です。最初から500件揃えようとすると整備に2ヶ月かかり、その間に本番が走り出して陳腐化します。「動くハーネス」を2週間で立ち上げ、運用しながら拡張する方が成功率が高いです。
Q. 評価モデルにはどのClaudeを使うべき?
A. 2026年5月時点では Sonnet 4.5を主軸、難所だけOpus 4.5 の二階建てが最適解です。分類・形式チェックはSonnetで十分、論理破綻検出や複雑な業務ロジック判定はOpusに任せます。詳細な比較はハーネス エンジニアリング claude API実装完全ガイドで扱っています。
Q. ハーネスの構築にどれくらいの工数がかかる?
A. 最小構成のCIループならエンジニア1人・2週間で立ち上がります。回帰評価まで含めると追加で3〜4週間、本番監視まで含めると合計2〜3ヶ月が目安です。ただし「業務ドメインに合わせた評価基準」の整備が最も時間を食うので、ドメインエキスパートを早期に巻き込むことが鍵です。
Q. テストとハーネスは両方必要?
A. はい、両方必須です。テストは決定論的な振る舞いを保証し、ハーネスは確率的な品質を観測する役割で、目的が違います。Claude Codeが書いたコードに対する単体テストはテスト、Claude Code自身の振る舞いに対する評価はハーネス、と整理してください。
Q. ハーネス自体が壊れていないかはどう確認する?
A. 「ハーネスのハーネス」として、固定の良ケース・悪ケースを月次でチェックします。良ケースが0.95、悪ケースが0.20付近で安定していれば、ハーネス自体は健全です。評価モデルのバージョンアップ時には必ずこの検証を回してください。
まとめ
claude code ハーネスエンジニアリングは、Claude Codeを業務適用するうえで避けて通れないインフラ層です。CIループ・回帰評価・本番監視の3層を分離し、それぞれに適切な速度と網羅性を割り当てることで、3ヶ月後・6ヶ月後の品質劣化を防げます。
「自社のClaude Code運用にハーネスを組み込みたい」「既存の評価フローを業務品質まで引き上げたい」といったご相談は、お問い合わせからお気軽にどうぞ。プロジェクトの段階に合わせて、最小構成から伴走します。