
こんにちは!株式会社雲海設計の技術部です。2026年6月現在、弊社の経営相談で急増しているのが「予測AIと生成AIの違いが社内で曖昧なまま、PoCを乱立させてしまい投資判断ができない」「需要予測のプロジェクトに生成AIを使おうとして頓挫した」という情シス・経営企画層からのご相談です。Gartnerが2026年4月に公表したレポートでは、AI投資の失敗プロジェクトの54%が「予測AIと生成AIのユースケース選定ミス」に起因しているとされています。
本記事では、予測aiと生成aiの違いというキーワードで検索する発注企業の意思決定者向けに、両者を目的・アルゴリズム・データ・業務適用の4軸で整理し、どちらを選ぶべきかの判断基準をコンサル視点で解説します。技術詳細ではなく、「自社の業務課題はどちらのAIで解くべきか」の意思決定材料の提供がゴールです。
- 予測AIは「過去データから未来の数値・分類を推定」、生成AIは「コンテキストから新しいコンテンツを生成」と目的が根本的に異なる
- 2026年最大の誤解は「生成AIで何でもできる」。需要予測・与信・故障検知は依然として予測AIの主戦場
- 選定の4軸は(1)目的、(2)アルゴリズム、(3)データ要件、(4)業務適用形態
- 失敗パターンの62%は「生成AIをKPI予測に使ってROIが出ない」(IDC Japan 2026年3月)
- 2026年の本流は予測AI×生成AIのハイブリッド。意思決定支援エージェントが新しい主戦場に
そもそも予測AIと生成AIの違いとは?2026年の定義整理
結論から言うと、予測AIは「過去データから未来や未知の値を推定する」ためのAI、生成AIは「学習済みパターンを元に新しいコンテンツ(テキスト・画像・コード等)を生成する」ためのAIです。両者はそもそも解こうとしている問題のクラスが違います。
なぜ今この違いが経営アジェンダになるのか
2025年までは「AI=機械学習=予測」が業務AIの中心でした。しかし2025年後半から生成AI・AIエージェントの企業導入が爆発的に進み、2026年現在、両者の役割分担が曖昧なままPoCが乱立しています。Forbes Japanが2026年5月に報じた調査では、国内大企業の67%が「AIプロジェクトの選定基準を再設計中」と回答しており、まさに整理の必要性が経営課題化しています。
「予測AIと生成AIは別物である。両者を混同したまま投資判断すると、ユースケースとアーキテクチャの両方でミスマッチが起きる」(MIT Sloan Management Review 2026年3月号)
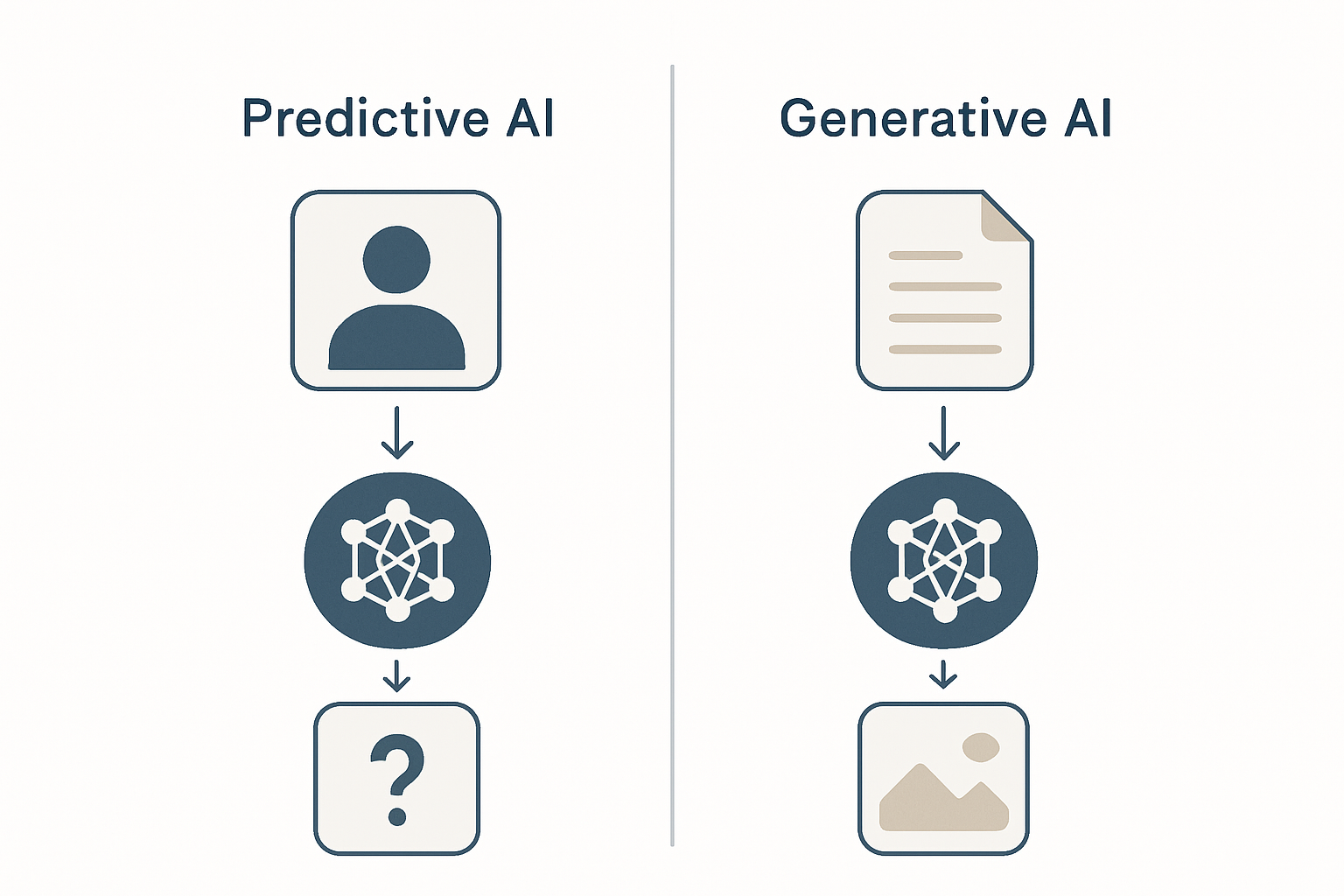
4軸で整理する予測AIと生成AIの違い
結論として、両者の違いは以下の4軸で漏れなく整理できます。発注企業が社内で議論する際の共通言語として使ってください。
| 軸 | 予測AI | 生成AI |
|---|---|---|
| 目的 | 未来値・分類の推定 | 新しいコンテンツの生成 |
| 主要アルゴリズム | 回帰・決定木・XGBoost・時系列モデル・ディープラーニング | Transformer (LLM)・Diffusion Model |
| データ要件 | 構造化データ中心・教師ラベル必須 | 非構造化データ・大規模事前学習が前提 |
| 業務適用形態 | バッチ/APIスコアリング・意思決定の補助 | 対話・文書生成・エージェント・UI埋め込み |
| 評価指標 | 精度・再現率・RMSE・AUC | 有用性・ハルシネーション率・人手評価 |
| 主な失敗モード | データドリフト・特徴量設計不足 | 幻覚・出典欠落・コンテキスト不足 |
軸1: 目的の違い - 何を解くためのAIか
予測AIが解くのは「Y = f(X) の Y を推定する」問題です。需要予測、与信スコア、解約予測、故障検知などが代表例で、出力は数値またはクラスラベル。一方、生成AIは「ある条件下でもっともらしい新規データを生成する」問題を解き、出力はテキスト、画像、コード、音声など多様です。
軸2: アルゴリズムの違い - モデル設計思想
予測AIは勾配ブースティング(XGBoost、LightGBM)や時系列モデル(Prophet、N-BEATS)が今も実務の中心です。少データでも高精度を出しやすく、特徴量設計のノウハウが価値を生みます。生成AIはTransformerベースの大規模言語モデルや拡散モデルが中心で、事前学習済みの基盤モデルをいかに業務文脈に適応させるかが論点です。
軸3: データ要件の違い
予測AIは「自社の業務データ+教師ラベル」がなければ始まりません。データクレンジングと特徴量エンジニアリングが投資の7割を占めます。生成AIは事前学習済みモデルを前提に、RAGやファインチューニングで自社データを「文脈として」供給するのが標準。RAGの仕組みと業務適用については別記事で詳説しています。
軸4: 業務適用形態の違い
予測AIは「裏方のスコアリングエンジン」として既存業務システムに組み込まれます。生成AIは「ユーザーと対話するインターフェース」として表に出てくることが多く、エージェント化することで業務フローそのものを変える力を持ちます。
どちらを選ぶべきか?業務課題別の判断フレーム
結論から言うと、「数値を当てたい」なら予測AI、「文章・画像・コード・対話を作りたい」なら生成AI。この一次切り分けで7割の案件は判別できます。
予測AIが圧倒的に強い業務
- 需要予測・在庫最適化: 時系列データと外部要因の組み合わせで構造化問題
- 与信・不正検知: 説明可能性・規制対応・実績指標が必須
- 解約予測・LTV予測: 行動ログから確率を出す典型タスク
- 設備故障予知(PdM): センサーデータ×異常検知
- 価格最適化: 弾力性モデリングとシミュレーション
これらに生成AIを使うのは原理的に筋が悪い。「LLMに需要を聞いた」では数値根拠が説明できず、稟議も通りません。
生成AIが圧倒的に強い業務
- 議事録・レポート自動生成: 非構造テキストの要約・整形
- カスタマーサポート1次対応: 対話とFAQ参照
- 営業提案書ドラフト: 過去案件の知見を組み合わせ生成
- コーディング支援: 仕様書からのコード生成・テスト生成
- 社内ナレッジ検索: RAGで自然言語問い合わせ
ハイブリッドが正解の業務
2026年に最も伸びている領域が「予測AIの結果を生成AIが説明・提案する」ハイブリッド型です。例えば需要予測モデルが出した数値を、生成AIエージェントが「なぜこの数値か」「どう発注を変えるべきか」を経営層向けに自然言語で説明する。AIエージェントの選定マトリクスとも密接に絡む論点です。
「2027年までに、エンタープライズAIプロジェクトの60%は、予測モデルと生成モデルを組み合わせたハイブリッド構成になる」(Gartner 2026年4月)
2026年の現場で起きている典型的な失敗パターン
弊社が2026年上半期に支援した案件から、ユースケース選定ミスの典型を3つ共有します。
失敗1: 「生成AIで需要予測」プロジェクトの破綻
大手小売A社が「ChatGPTに過去販売データを投げて予測させる」PoCを実施。精度はXGBoost比で30%低く、ハルシネーションで根拠不明の数値も出力され、3ヶ月で中止。原因は「数値推定問題に生成AIを当てた」目的軸のミスマッチです。
失敗2: 「予測AIでチャットボット」の硬直化
金融B社が古い分類モデルベースのチャットボットに固執し、自然言語対応の柔軟性が出ず顧客満足度が低下。生成AI+RAGに切り替えるべき業務を、過去資産の延命で乗り切ろうとして失敗しました。
失敗3: ガバナンス設計なしの全社生成AI導入
製造C社が「全社員に生成AI解放」を宣言したが、ハルシネーションによる誤情報拡散と機密情報漏洩リスクが顕在化し、3ヶ月で利用制限。AIセキュリティリスクの7分類を踏まえたガバナンス設計が前提条件です。
発注企業のための選定チェックリスト
意思決定の場で使えるチェックリストを置いておきます。YESが多い側のAIを選ぶのが基本方針です。
予測AI寄りに振るべきサイン
- 出力が数値またはクラスラベルである
- 過去データ(教師ラベル付き)が3年分以上ある
- 精度・誤差の定量評価が必須である(規制・経営報告)
- 説明可能性(なぜその予測か)が問われる
- 業務システムにバッチ/APIで組み込みたい
生成AI寄りに振るべきサイン
- 出力がテキスト・画像・コード・対話である
- 非構造データ(文書・チャット・画像)が主役
- ユーザーと自然言語でやり取りする必要がある
- 業務フロー自体を再設計する余地がある
- RAGまたはエージェント設計を許容できる
投資配分の目安(2026年版)
| 企業規模 | 予測AI | 生成AI | ハイブリッド/エージェント |
|---|---|---|---|
| 大企業 | 40% | 30% | 30% |
| 中堅 | 30% | 50% | 20% |
| 中小 | 20% | 70% | 10% |
中小企業はパッケージ化された生成AI SaaSから入るのが投資効率上は妥当。一方、大企業は既存の予測AI資産(需要予測・与信モデル)を生成AIで「説明可能化」するのがROIの高い打ち手です。
雲海設計の支援アプローチ
弊社では「予測AIと生成AIのユースケース仕分け」を起点とした伴走支援を提供しています。具体的には、(1)業務課題の棚卸しと4軸での分類、(2)PoC設計と評価指標定義、(3)本番実装とガバナンス設計、までを一気通貫で支援します。
詳細はITコンサルティングおよびDXソリューションのページをご覧ください。「自社の課題が予測AI寄りか生成AI寄りか診断してほしい」というご相談はお問い合わせからお気軽にどうぞ。
よくある質問
Q. 予測AIはもう古い技術ではないですか?
A. いいえ、2026年現在も需要予測・与信・故障検知などの数値推定領域では予測AIが圧倒的に高精度です。生成AIで代替できる領域とそうでない領域を分けて理解することが重要です。
Q. 生成AIで予測タスクは本当に不可能ですか?
A. 可能ではありますが、精度・コスト・説明可能性のすべてで予測AIに劣るのが2026年時点の実情です。ただし「予測結果を自然言語で説明する」用途は生成AIの独壇場です。
Q. 中小企業はどちらから始めるべきですか?
A. 中小企業はパッケージ化された生成AI SaaS(議事録・チャット・ドキュメント生成)から始めるのが投資効率上は最適です。予測AIは内製・外注ともにデータ整備コストが重く、ROI回収まで時間がかかります。
Q. ハイブリッド構成はどう設計しますか?
A. 典型は「予測AIの数値出力 → 生成AIによる自然言語説明・推奨アクション提示」のパイプラインです。AIエージェントのオーケストレーション層で両者を統合する設計が2026年の主流になりつつあります。
Q. 社内に予測AI人材も生成AI人材もいません。何から始めるべきですか?
A. まずユースケース仕分けを外部コンサルと行い、社内に「AI課題分類スキル」を残すことから始めることをお勧めします。技術選定はその後で十分間に合います。