
こんにちは!株式会社雲海設計の技術部です。
「Claude CodeやCursorが書いたPRが大量に積まれて、人間レビューが追いつかない」「AI生成コードの一部はテストが通るのに、レビューしてみると設計思想がバラバラ」「同じ観点を毎回コメントで指摘していて、生産性が逆に落ちている」——2025年にAIコーディングエージェントが本格導入され、2026年に入ってからハーネスエンジニアリング コードレビューの相談が週次で入ってきます。本記事では、AI生成コードのレビューを自動化しつつ品質を担保するためのハーネスエンジニアリング コードレビューの設計を、観点の評価項目化と人間レビューとのハイブリッド運用という2軸で整理します。
TL;DR
ハーネスエンジニアリング コードレビューは「評価ハーネス・自動採点・Human-in-the-Loop」の3層構造で設計する
レビュー観点は機能正当性・設計品質・セキュリティ・運用性の4分類に評価項目化し、各項目を0〜2点でスコアリング
AI採点だけでは精度が出ない。低スコアと境界スコアの2レーンを必ず人間に回す
2026年の現場では、PRの約6〜7割をハーネスで先に処理し、人間は設計判断に集中するのが標準形
ハーネス自体の品質は評価セットでメタ評価する。これを怠るとレビュー基準が静かに腐る
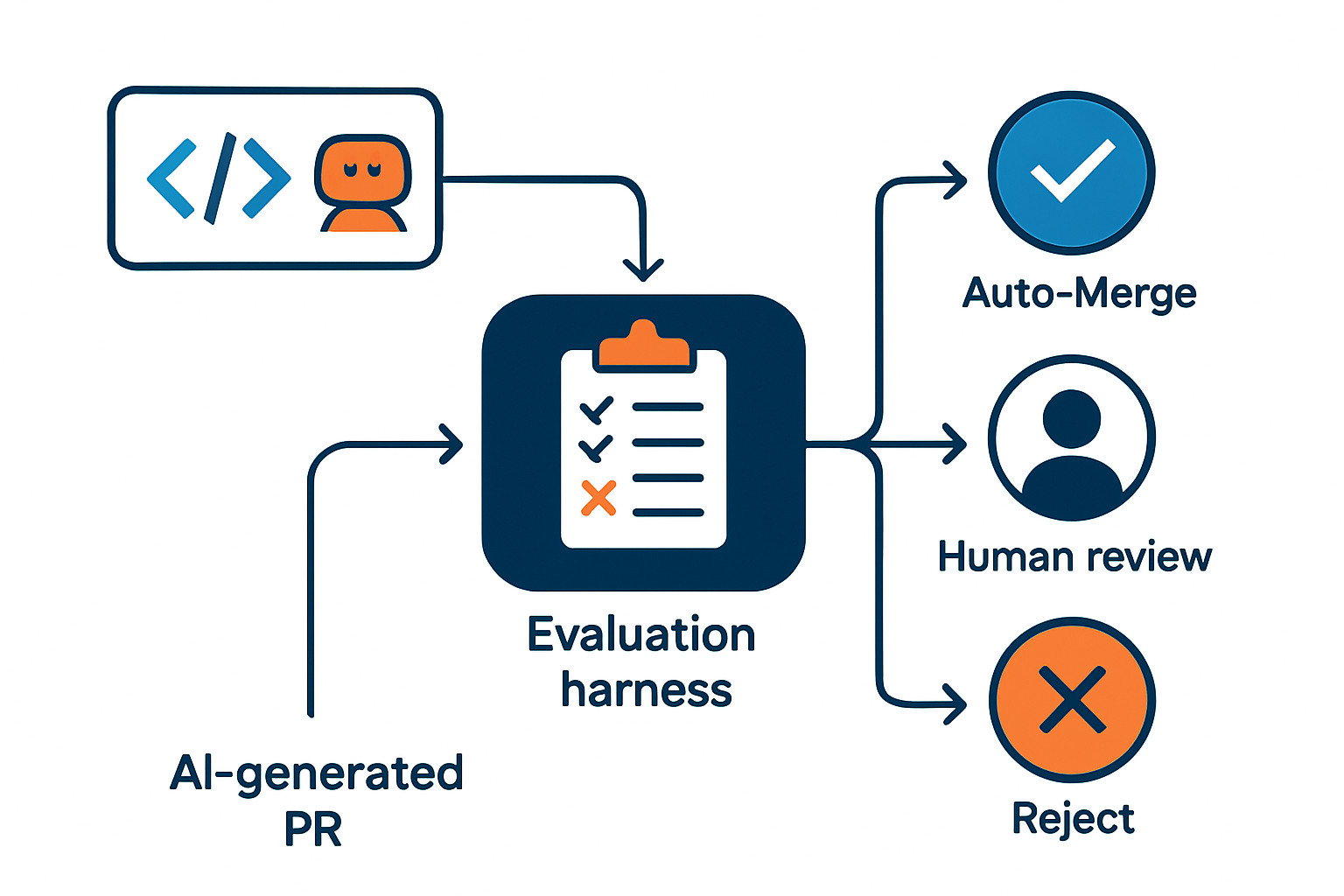
なぜ2026年にハーネスエンジニアリング コードレビューが必須なのか?
結論から言うと、AI生成コードの量が人間レビューのスループットを構造的に超えたからです。GitHubが2025年末に公開したOctoverseでも、Copilot/Claude Code経由の自動生成PRは前年比で3倍以上に増加しており、レビュアー1人あたりのPR待ち行列が常時2〜3倍に膨らんでいる現場が多数報告されています。
従来のレビュー運用が破綻する3つの理由
量の爆発:1人のエンジニアがエージェント経由で1日10〜30PRを発行する時代に、目視レビューでは絶対に間に合わない
観点のブレ:レビュアーごとに指摘ポイントが違い、AI生成コードの一貫性が保てない
疲労による見逃し:似たコードが大量に流れると注意力が落ち、セキュリティ上の致命傷を見逃す
つまり、レビューの「量」と「観点の標準化」を機械側に寄せて、人間は設計判断と最終ゲートに集中させる必要があります。これがハーネスを使ったコードレビュー自動化の出発点です。なお、ハーネスエンジニアリング自体の概念はハーネスエンジニアリングとは?LLM時代に必須の新常識で詳しく整理しているので、未読の方は併せてご参照ください。
レビュー観点をどう評価項目化するか?
結論から言うと、観点を4分類×複数項目のルーブリックに落とし、各項目を離散スコアで採点するのが最も再現性が高い設計です。Anthropicが2025年に公開したコード評価ベンチマークSWE-Benchの拡張系でも、ルーブリック化したレビュー観点のほうが自由記述評価より人間との相関が高いという結果が示されています。
4分類のレビューカテゴリ
| カテゴリ | 評価する内容 | 主な評価項目 |
|---|---|---|
| 機能正当性 | 仕様通りに動くか | テスト網羅、エッジケース、回帰 |
| 設計品質 | 保守可能か | 責務分離、命名、重複、複雑度 |
| セキュリティ | 事故らないか | 入力検証、認可、秘密情報、依存 |
| 運用性 | 本番で耐えるか | ログ、エラーハンドル、性能、監視 |
採点ルーブリックの実例
各項目は0(重大欠陥)/ 1(要改善)/ 2(合格)の3段階で採点します。曖昧さを残すと評価がブレるので、各点数の判定条件を必ず文章化します。
rubric:
security_input_validation:
description: "外部入力の検証が適切か"
score_2: "全ての外部入力がスキーマ検証され、エラー時の挙動が明示"
score_1: "検証はあるが、境界値や型変換の漏れがある"
score_0: "未検証のまま下層関数に渡されている"
design_responsibility:
description: "単一責務原則の遵守"
score_2: "関数・クラスの責務が1つに収束"
score_1: "責務の分離が曖昧だが、リファクタ可能な範囲"
score_0: "複数責務が1関数に混在、副作用あり"
スコアの集約と閾値
カテゴリ別平均を算出し、セキュリティだけは最低点でゲート(1項目でも0なら即リジェクト)
総合スコアは1.6以上で自動マージ候補、1.2〜1.6で人間レビュー、1.2未満で自動差し戻しを初期値にする
閾値は運用しながら4週間ごとに調整。固定すると現場感とズレる
ハーネスはどう実装するか?
結論から言うと、CIに統合された軽量パイプラインとして実装し、LLM採点と決定論的チェックを並列実行するのが最も運用負荷が低い構成です。LLMだけに頼ると採点がブレ、静的解析だけでは設計品質が見えないため、両方を組み合わせます。
パイプラインの全体像
graph LR
A[AI生成PR] --> B[静的解析]
A --> C[テスト実行]
A --> D[LLMルーブリック採点]
B --> E[スコア集約]
C --> E
D --> E
E --> F{総合判定}
F -->|高スコア| G[自動マージ候補]
F -->|中スコア| H[人間レビュー]
F -->|低スコア| I[自動差し戻し]
LLM採点プロンプトの基本形
REVIEW_PROMPT = """
あなたはシニアエンジニアとしてコードレビューを行います。
以下のルーブリックに厳密に従い、各項目を0/1/2で採点してください。
判定が曖昧な場合は必ず低い方の点数を付けてください。
# ルーブリック
{rubric_yaml}
# 差分
{diff}
# 出力形式(JSON厳守)
{{
"scores": {{ "item_id": {{"score": 0|1|2, "reason": "..."}} }},
"blocking_issues": ["..."]
}}
"""
実装で押さえるべき4つのポイント
差分のみを渡す:ファイル全体を入れるとトークン浪費+採点がブレる
JSON Schemaで出力強制:自由記述させない。集約処理の前提が崩れる
同じPRを3回採点して中央値を取る:単発採点は2〜3割の確率で過大評価が出る
blocking_issuesは別系統で扱う:スコアに関係なく1件でもあれば人間に回す
具体的なエージェント連携や評価ハーネスの設計詳細は、ハーネスエンジニアリング ベストプラクティスでも実装パターンを整理しています。
人間レビューとのハイブリッド運用はどう設計するか?
結論から言うと、ハーネスのスコア帯ごとにレビュー強度を変える「3レーン運用」が現場で最もワークします。全てを人間が見るのは破綻し、全てを自動化すると重大事故が起きるためです。
3レーン運用の標準形
| レーン | 条件 | 処理 | 人間の関与 |
|---|---|---|---|
| Green | 総合1.6以上+blocking無し | 自動マージ候補 | サンプリングで10%抜き取り監査 |
| Yellow | 総合1.2〜1.6 or 設計変更含む | 人間レビュー必須 | 1人レビュー+Approve必須 |
| Red | 総合1.2未満 or blocking有り | 自動差し戻し | 修正後再投入 |
Green帯でも油断しないための工夫
「自動マージ候補」と「自動マージ」は別物です。最終的なマージ判断は、たとえ低リスクでも人間の合意(Approve)を残すべき、というのが2026年時点での実務的な落としどころです。
サンプリング監査:Green帯の10%を週次で抜き取って人間が再評価し、ハーネス精度を確認
変更影響範囲フィルタ:認証・課金・データ削除に触れるPRは自動的にYellow扱いに格上げ
連続Greenの上限:同一エージェントの連続自動マージは10件で打ち切り、強制レビューを挟む
Yellow帯のレビューを高速化するコツ
人間レビュアーの負荷を下げるため、ハーネスの採点理由をそのままPRコメントに自動投稿します。レビュアーは「ハーネスがどこを問題視したか」を起点に確認できるので、ゼロから読むより50〜70%時間が短縮します。AIが暴走しないためのガードレール設計はAIに任せるのがちょっと怖い?暴走させないガードレール設計でも整理していますので、併せてご参照ください。
ハーネス自体の品質はどう担保するか?
結論から言うと、ハーネスの採点を「正解付き評価セット」で定期的にメタ評価することが必須です。これを怠ると、いつの間にかレビュー基準が緩んでいて、半年後に技術的負債が大量に発生します。
メタ評価セットの作り方
過去の人間レビュー結果を50〜100件サンプルし、各PRに「人間が付けた最終スコア」を正解として紐付け
ハーネスにそれらを採点させ、人間との相関係数(できれば0.7以上)を測定
相関が0.5を切ったらルーブリックかプロンプトを見直す
四半期ごとに評価セットを20%入れ替えし、現場の変化に追従させる
よくある劣化パターン
採点インフレ:モデルアップデート後にスコアが全体的に上振れする
カテゴリ偏重:セキュリティだけ厳しく、設計品質を見逃すようになる
新パターン未対応:新しいフレームワークやエージェントの癖をルーブリックが捕捉できない
運用チェックリスト
| 頻度 | 確認項目 |
|---|---|
| 毎週 | Green帯サンプリング監査、blocking発生件数 |
| 毎月 | カテゴリ別スコア分布、誤判定PRの分析 |
| 四半期 | 評価セット更新、相関係数の再測定、閾値調整 |
雲海設計の支援アプローチ
当社では、AIコーディングエージェントを業務開発に導入しているお客様に対して、ハーネス設計・ルーブリック作成・CI統合・運用メトリクス整備までをパッケージで支援しています。Claude Code・Cursor・Devinといったエージェントごとの癖を踏まえた設定や、既存のレビュー文化を壊さない段階的な移行設計が得意です。
AI生成PRが急増してレビューが回らなくなった
レビュー観点の標準化を進めたいが時間が取れない
ハーネスを作ったが採点品質に自信が持てない
こうした課題があれば、ITコンサルティングやDXソリューションのページから概要をご覧いただき、お問い合わせからご相談ください。エージェント選定段階からの設計相談も承っています。
よくある質問
Q. ハーネスエンジニアリング コードレビューは小規模チームでも導入できますか?
A. 可能です。むしろ少人数チームほど効果が大きく、5〜10名規模なら2〜3週間で初期ハーネスを立ち上げられます。最初はルーブリックを5〜8項目に絞り、CIにLLM採点ステップを1つ追加するところから始めるのが現実的です。
Q. LLM採点のコストはどの程度かかりますか?
A. 差分のみを渡す前提で、PR1件あたり数円〜数十円のオーダーが標準です。月間500PRでも数千円〜2万円程度に収まるケースが多く、人間レビュー時間の削減効果と比べれば十分にペイします。
Q. ハーネスが厳しすぎてPRが通らない場合はどうすれば?
A. ルーブリックの採点条件を見直す前に、まず閾値を一段下げて1〜2週間運用してみてください。多くのケースでは閾値の問題ではなく、特定カテゴリ(特にセキュリティの過剰判定)が原因です。誤判定PRを20件ほど集めれば、原因項目はほぼ特定できます。
Q. 人間レビュアーの役割はどう変わりますか?
A. 「文法的な指摘」から「設計判断と境界決定」にシフトします。ハーネスが拾えないドメイン知識・アーキテクチャの一貫性・チーム規約の解釈などに人間の時間を集中させる形になり、レビュー業務の知的密度はむしろ上がります。
Q. ハーネスとAIガードレールはどう違いますか?
A. ハーネスは事後の評価・採点、ガードレールは事前・実行時の制約です。両者は補完関係にあり、コードレビュー領域では「ガードレールで危険操作を遮断+ハーネスで品質を採点」という二段構えが2026年の標準的な設計になっています。